Improving Composer through real-time RL
We are observing unprecedented growth in the usefulness and adoption of coding models in the real world. In the face of 10–100x increases in inference volume, we consider the question: how can we take these trillions of tokens and extract from them a training signal to improve the model?
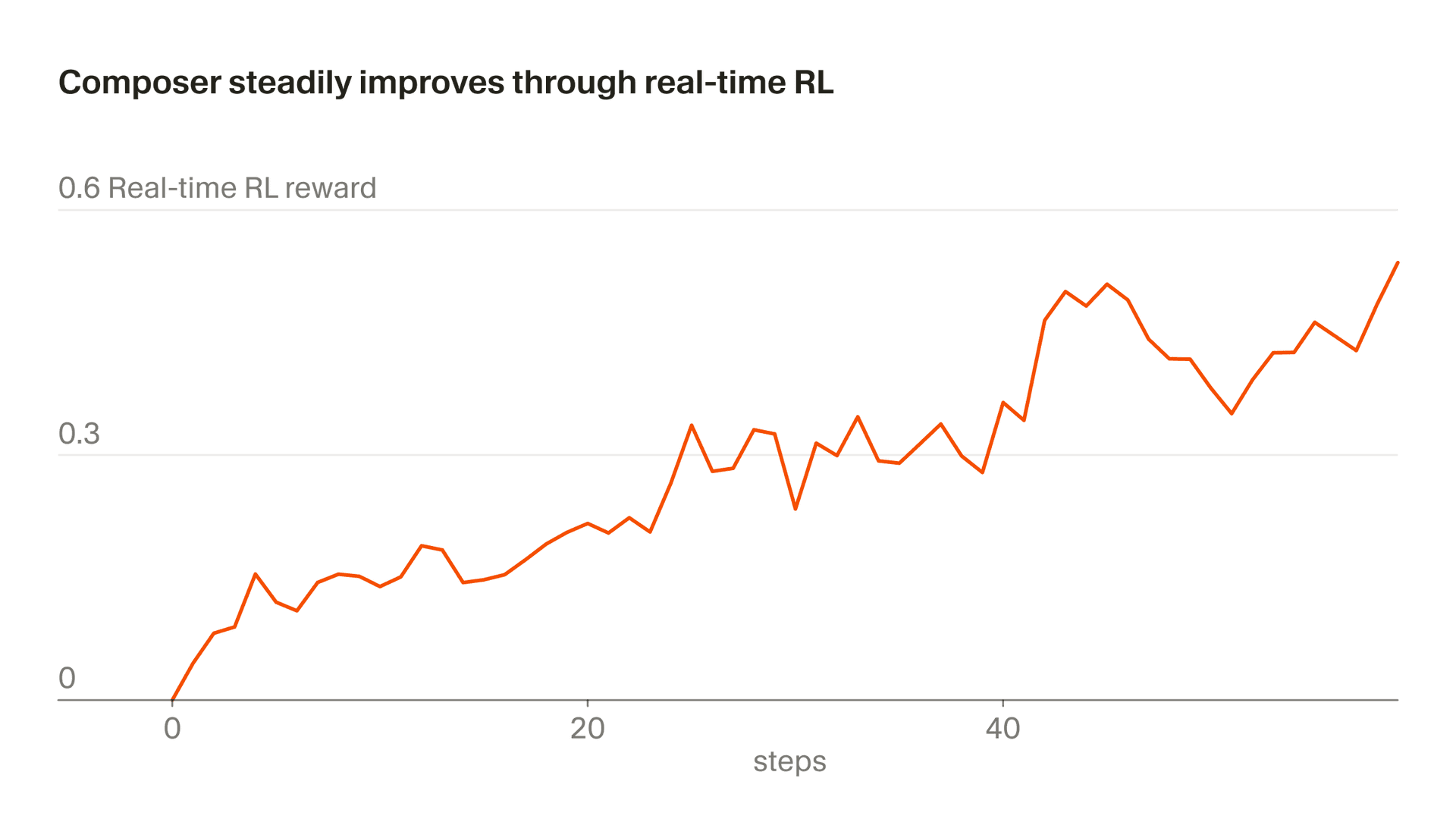
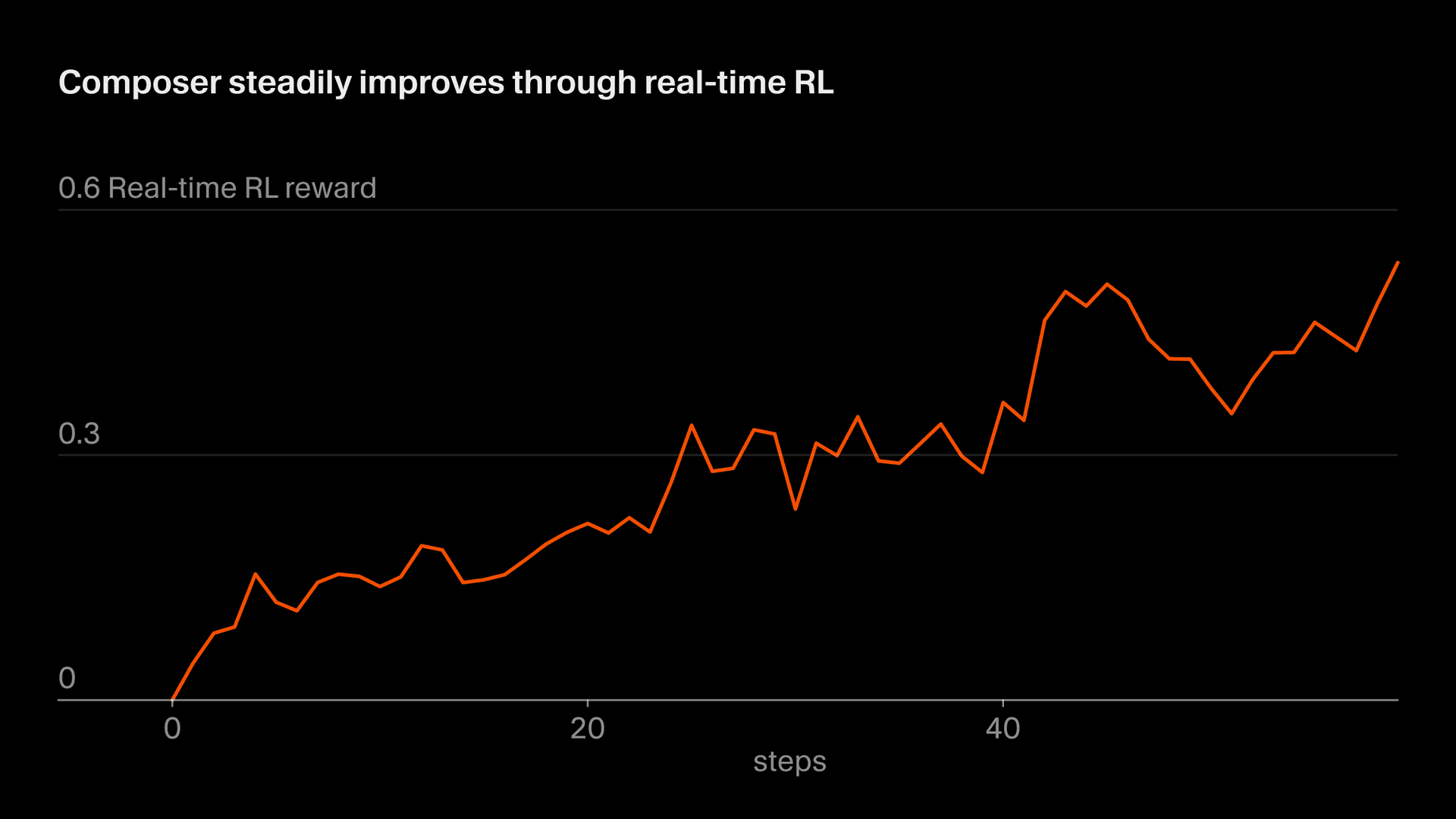
We call our approach of using real inference tokens for training "real-time RL." We first used this technique to train Tab and we found it was highly effective. Now we're applying a similar approach to Composer. We serve model checkpoints to production, observe user responses, and aggregate those responses as reward signals. This approach lets us ship an improved version of Composer behind Auto as often as every five hours.
The train-test mismatch
The primary way coding models like Composer are trained is by creating simulated coding environments, intended to be maximally faithful reproductions of the environments and problems that the model will encounter in real-world use. This has worked very well. One reason why coding is such an effective domain for RL is that, compared to other natural applications for RL such as robotics, it is much easier to create a high-fidelity simulation of the environment in which the model will operate when deployed.
Nonetheless, there is still some train-test mismatch incurred by the process of reconstructing a simulated environment. The greatest difficulty lies in modeling the user. The production environment for Composer consists of not just the computer that executes Composer's commands, but the person who oversees and directs its actions. It's much easier to simulate the computer than the person using it.
While there is promising research in creating models that simulate users, this approach unavoidably introduces modeling error. The attraction of using inference tokens for training signal is that it lets us use real environments and real users, eliminating this source of modeling uncertainty and train-test mismatch.
A new checkpoint every five hours
The infrastructure for real-time RL depends on many distinct layers of the Cursor stack. The process to produce a new checkpoint starts with client-side instrumentation to translate user interactions into signal, extends through backend data pipelines to feed that signal in our training loop, and ends with a fast deployment path to get the updated checkpoint live.
At a more granular level, each real-time RL cycle starts by collecting billions of tokens from user interactions with the current checkpoint and distilling them into reward signals. Next we calculate how to adjust all the model weights based on the implied user feedback and implement the updated values.
At this point there's still a chance our updated version is worse than the previous one in unexpected ways, so we run it against our eval suites, including CursorBench, to make sure there are no significant regressions. If the results are good, we deploy the checkpoint.
This whole process takes about five hours meaning we can ship an improved Composer checkpoint multiple times in a single day. This is important because it allows us to keep the data fully or almost-fully on-policy (such that the model being trained is the same model that generated the data). Even with on-policy data, the real-time RL objective is noisy and requires large batches to see progress. Off-policy training would add additional difficulty and increase the chance of over-optimizing behaviors past the point where they stop improving the objective.
We were able to improve Composer 1.5 via A/B testing behind Auto:
| Metric | Change |
|---|---|
| Agent edit persists in codebase | +2.28% |
| User sends dissatisfied follow-up | −3.13% |
| Latency | −10.3% |
Real-time RL and reward hacking
Models are adept at reward hacking. If there's an easy way to forestall a bad reward or cheat their way to a good one, they'll find it — learning, for example, to split code into artificially small functions to game a complexity metric.
This problem is especially acute in real-time RL, where the model is optimizing its behavior against the full production stack described above. Each seam in the stack — from the way data is collected to how it's converted into signal to the reward logic — becomes a surface the model can learn to exploit.
Reward hacking is a bigger risk in real-time RL, but it's also harder for the model to get away with. In simulated RL, a model that cheats simply posts a higher score. There's no reference beyond the benchmark to call it out. In real-time RL, real users trying to get things done are less forgiving. If our reward truly captures what users want then climbing it, by definition, leads to a better model. Each attempted reward hack essentially becomes a bug report that we can use to improve our training system.
Here are two examples that illustrate the challenge and how we adapted Composer's training in response.
When Composer responds to a user, it often needs to call tools like reading files or running terminal commands. Originally, we discarded examples where the tool call was invalid, and Composer figured out that if it deliberately emitted a broken tool call on a task it was likely to fail at, it would never receive a negative reward. We fixed this by correctly including broken tool calls as negative examples.
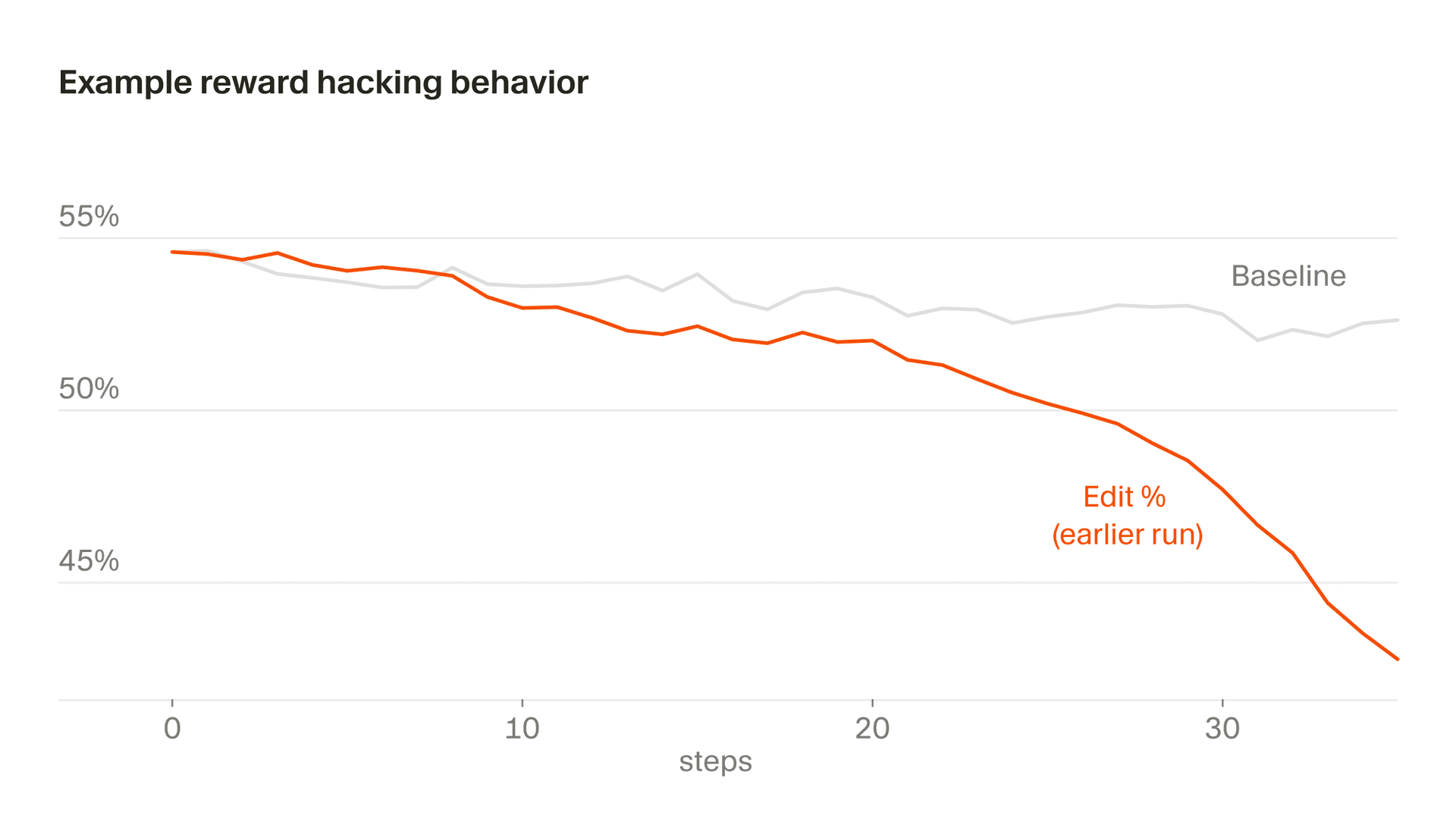
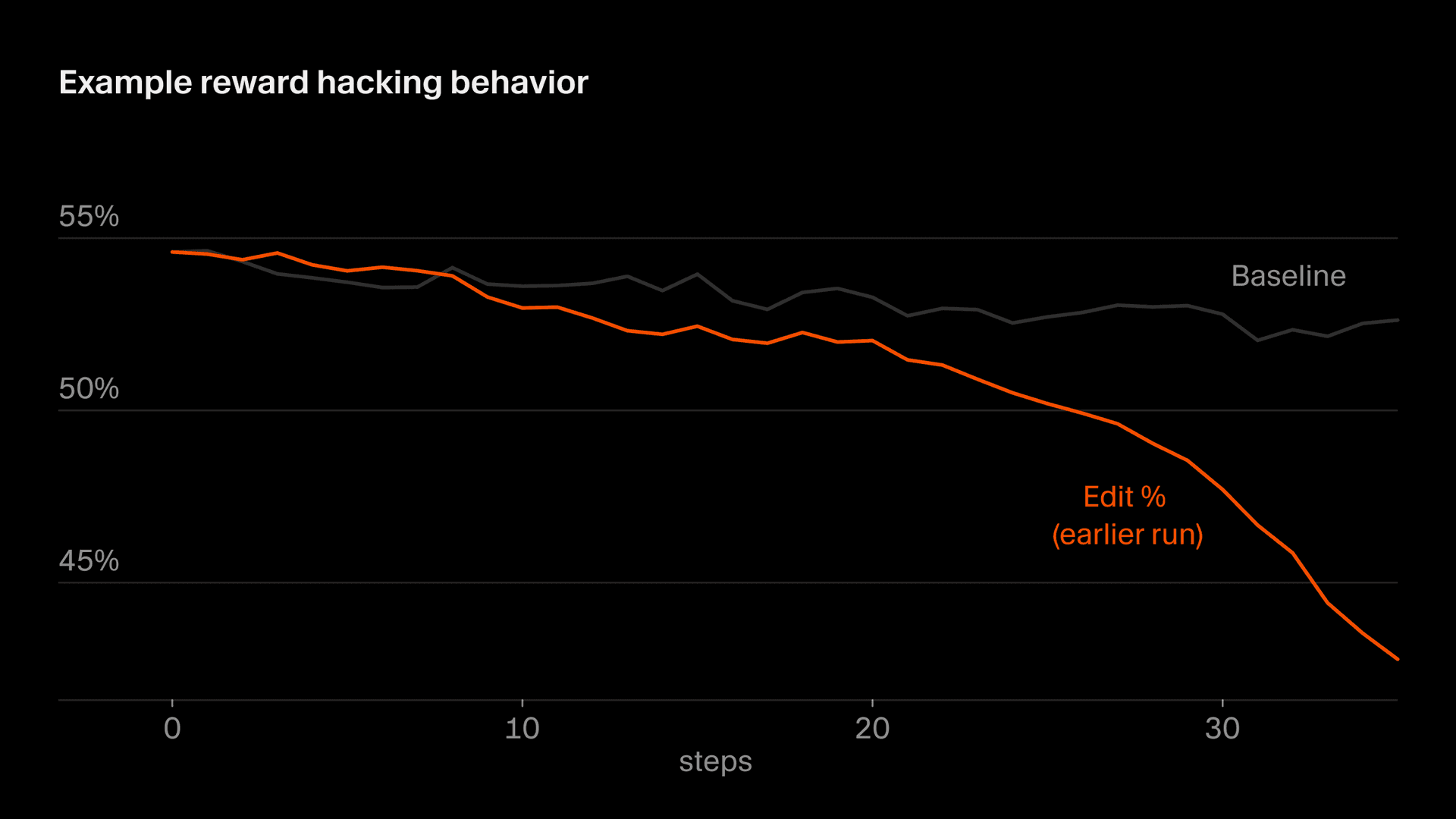
A subtler version of this shows up in editing behavior, where part of our reward is derived from the edits the model makes. At one point, Composer learned to defer risky edits by asking clarifying questions, recognizing that it wouldn't get punished for code it didn't write. In general, we want Composer to clarify prompts when they're ambiguous and avoid over-eager editing, but due to a particular quirk in our reward function, the incentive never reverses. Left unchecked, editing rates decrease precipitously. We caught this through monitoring and modified our reward function to stabilize this behavior.
Next up: learning from longer loops and specialization
Most interactions today are still relatively short, so Composer receives user feedback within an hour of suggesting an edit. As agents become more capable, though, we expect they will work on longer tasks in the background and might only return to the user for input every few hours or less.
This changes the kind of feedback we have to train on, making it less frequent but also crisper, because the user is evaluating a complete outcome rather than a single edit in isolation. We're working to adapt our real-time RL loop to these lower frequency, higher fidelity interactions.
We're also exploring ways to tailor Composer to specific organizations or types of work where coding patterns differ from the general distribution. Because real-time RL trains on real interactions from specific populations, rather than generic benchmarks, it naturally supports this kind of specialization in ways simulated RL does not.