Introducing Composer 2
Composer 2 is now available in Cursor.
It's frontier-level at coding and priced at $0.50/M input and $2.50/M output tokens, making it a new, optimal combination of intelligence and cost. We also released a technical report on how we trained it.


Frontier-level coding intelligence
We're rapidly improving the quality of our model. Composer 2 delivers large improvements on all benchmarks we measure, including Terminal-Bench 2.01 and SWE-bench Multilingual:
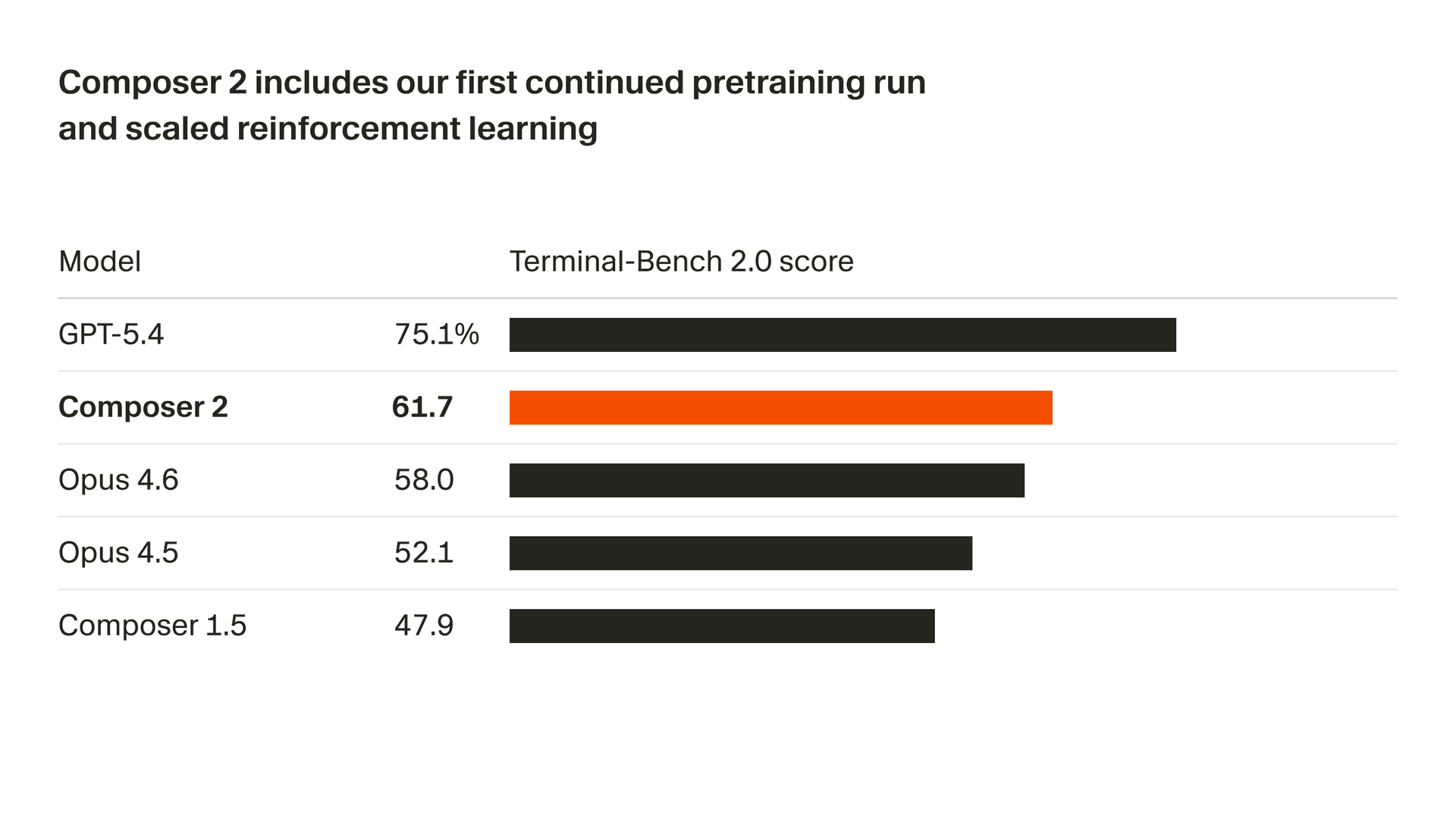
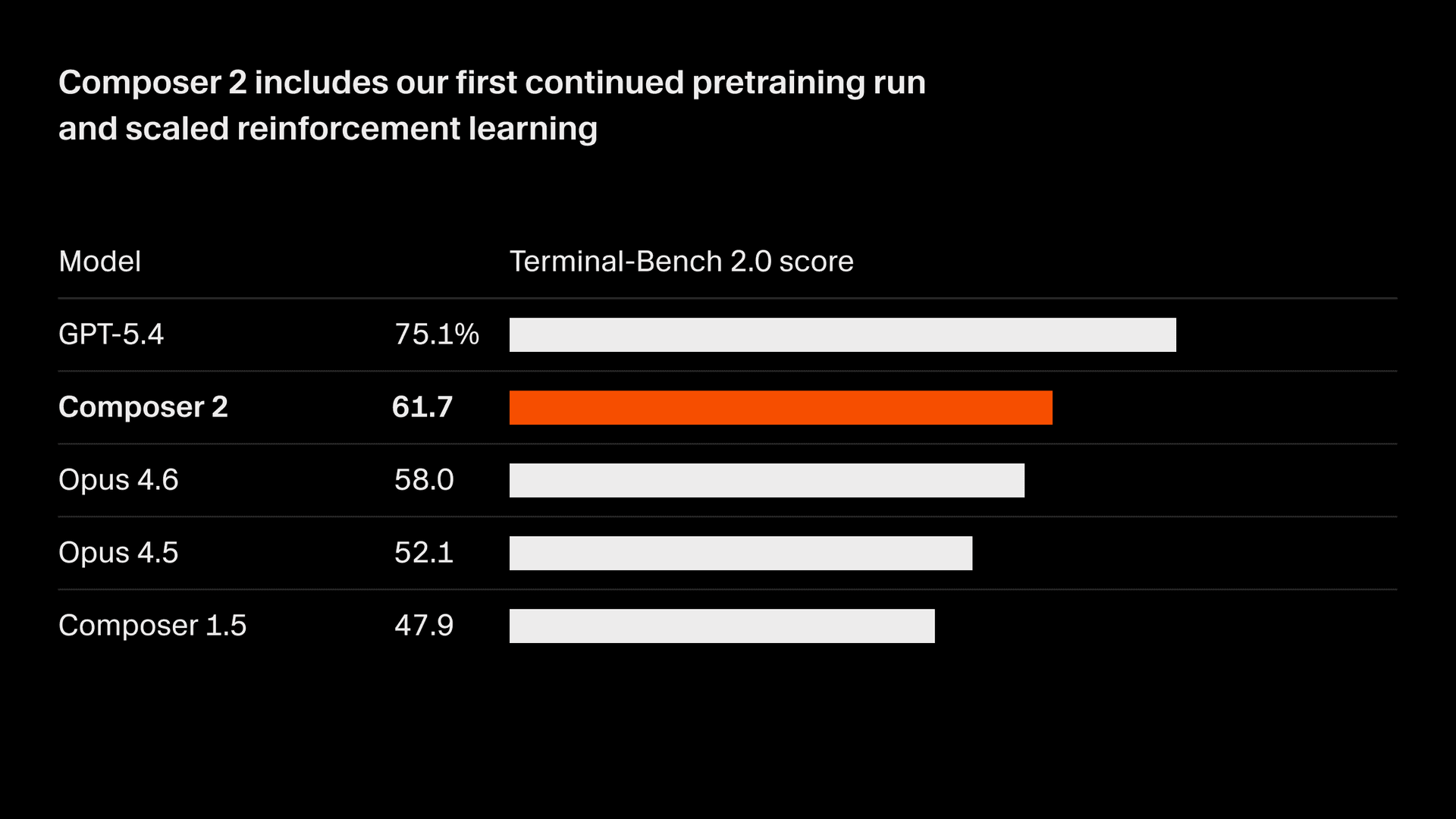
| Model | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
These quality improvements come from our first continued pretraining run, which provides a far stronger base to scale our reinforcement learning.
From this base, we train on long-horizon coding tasks through reinforcement learning. Composer 2 is able to solve challenging tasks requiring hundreds of actions.
Try Composer 2
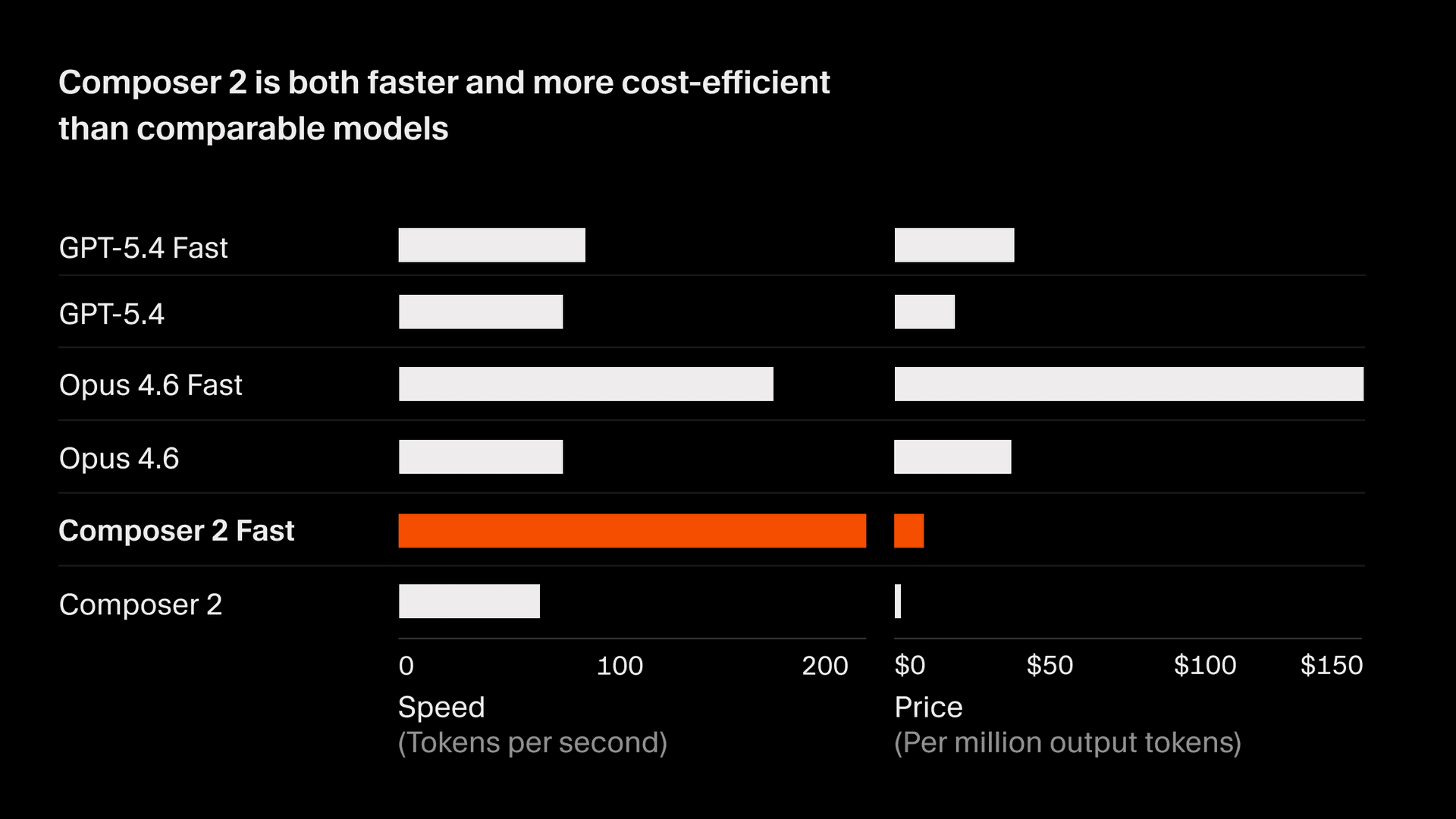
Composer 2 is priced at $0.50/M input and $2.50/M output tokens.
There is also a faster variant with the same intelligence at $1.50/M input and $7.50/M output tokens, which has a lower cost than other fast models2. We're making fast the default option. See the current Composer model docs for full details.

On individual plans, Composer usage is part of the First-party models pool with generous usage included. Try Composer 2 today in Cursor or in the early alpha of our new interface.
- Terminal-Bench 2.0 is an agent evaluation benchmark for terminal use maintained by the Laude Institute. Anthropic model scores use the Claude Code harness and OpenAI model scores use the Simple Codex harness. Our Cursor score was computed using the official Harbor evaluation framework (the designated harness for Terminal-Bench 2.0) with default benchmark settings. We ran 5 iterations per model-agent pair and report the average. More details on the benchmark can be found at the official Terminal Bench website. For other models besides Composer 2, we took the max score between the official leaderboard score and the score recorded running in our infrastructure. ↩
- Tokens per second (TPS) for all models are from a snapshot of Cursor traffic on March 18th, 2026. Token sizing for Composer and GPT models are similar. Anthropic tokens are ~15% smaller and the TPS number is normalized to reflect that. Similarly, output token price for non-Anthropic models was scaled to match the same ~15% change. Speed may vary depending on provider capacity and improvements over time. ↩