Iterating with shadow workspaces
Here’s a recipe for failure: paste a few relevant files into a Google Doc, send the link to your favorite p60 software engineer who knows nothing about your codebase, and ask them to fully and correctly implement your next PR inside the doc.
Ask an AI to do the same and it will also, predictably, fail.
Now, instead give them remote access to your development environment, with the ability to see lints, go to definitions, and run code, and you may actually expect them to be somewhat helpful.
We believe that one of the things that will let AIs write more of your code is the ability to iterate in your development environment. But naively letting AIs run loose in your folder results in chaos: imagine writing out a reasoning-intense function only for an AI to overwrite it, or trying to run your program only for an AI to insert code that doesn’t compile. To actually be helpful, the AI iteration needs to happen in the background, without affecting your coding experience.
To achieve this, we implemented what we call the shadow workspace into Cursor. In this blog post, I will first outline our design criteria, and then describe the implementation that exists in Cursor as of the time of writing (a hidden Electron window) and where we intend to take it in the future (a kernel-level folder proxy).

Design criteria
We want the shadow workspace to achieve the following goals:
-
LSP-usability: the AIs should see lints from their changes, be able to go to definitions, and more generally be able to interact with all parts of the language server protocol (LSP).
-
Runnability: the AIs should be able to run their code and see the output.
We initially focus on LSP-usability.
The goals should be achieved subject to the following requirements:
-
Independence: the user’s coding experience must be unaffected.
-
Privacy: the user’s code should be safe (e.g., by having it all be local).
-
Concurrency: several AIs should be able to do their work concurrently.
-
Universality: it should work for all languages and all workspace setups.
-
Maintainability: it should be written with as little and as isolatable code as possible.
-
Speed: there should be no minute-long delays anywhere, and there should be enough throughput for hundreds of branches of AIs.
Many of these reflect the reality of building a code editor for more than a hundred thousand users. We really don’t want to negatively affect anyone’s coding experience.
Achieving LSP-usability
Letting AIs get lints for their edits is one of the most impactful ways to improve code generation performance when holding the underlying language model fixed. Not only do lints allow going from 90% working code to 100% working code, but they are also very helpful in context-constrained situations, when the AI may need to make an educated guess about what method or service to call on the first try. The lints can help identify places where the AI needs to ask for more information.

LSP-usability is also simpler than runnability, because almost all language servers can operate on files that aren’t written to the file system (and as we will see later, involving the file system makes things quite a bit more difficult). So let’s start here! In the spirit of our fifth requirement, maintainability, we first tried the simplest possible solutions.
The simple solutions that don’t work
Cursor being a fork of VS Code means that we already have very easy access to language servers. In VS Code, every open file is represented by a TextModel object, which stores the current state of the file in memory. Language servers read from these text model objects instead of from disk, which is how they can give you completions and lints as you type (rather than just when you save).
Suppose an AI makes an edit to the file lib.ts. We obviously cannot modify the existing TextModel object corresponding to lib.ts, because the user may be editing it at the same time. Nevertheless, a plausible-sounding idea is to create a copy of the TextModel object, detach the copy from any real file on disk, and let the AI edit and get lints from that object. This could be accomplished by the following 6 lines of code.
async getLintsForChange(origFile: ITextModel, edit: ISingleEditOperation) {
// create the copied in-memory TextModel and apply the AI edit to it
const newModel = this.modelService.createModel(origFile.getValue(), null);
newModel.applyEdits([edit]);
// wait for 2 seconds to allow language servers to process the new TextModel object
await new Promise((resolve) => setTimeout(resolve, 2000));
// read the lints from the marker service, which internally routes to the correct extension based on the language
const lints = this.markerService.read({ resource: newModel.uri });
newModel.dispose();
return lints;
}This solution is clearly stellar on maintainability. It is also great for universality, because most people will already have installed and configured the right language-specific extensions for their project. Concurrency and privacy are trivially satisfied.
The problem is independence. While making a copy TextModel means that we aren’t directly modifying the file that the user is editing, we do still tell the language server, the same language server that the user is using, about the existence of our copied file. This causes problems: go-to-references results will include our copied file, languages like Go that have a multi-file default namespace scope will complain about duplicated declarations for all functions both in the copied file and in the original file that the user may be editing, and languages like Rust where files are only included if they are explicitly imported somewhere else will not give you any errors at all. There are likely a lot more problems like this.
You may think that these problems sound minor, but independence is absolutely critical for us. If we degrade the normal experience of editing code even slightly, it won’t matter how good our AI features are — people, including myself, would just not use Cursor.
We considered a few other ultimately failing ideas too: spawning off our own tsc or gopls or rust-analyzer instances outside of the VS Code infrastructure, duplicating the extension host process where all VS Code extensions are run so that we can run two copies of each language server extension, and forking all popular language servers to support multiple different versions of files and then bundling those extensions into Cursor.
The current shadow workspace implementation
We ended up implementing the shadow workspace as a hidden window: whenever an AI wants to see lints for code that it wrote, we spawn a hidden window for the current workspace, and then we do the edit in that window instead, reporting back the lints. We reuse the hidden window between requests. This gives us (almost*) full LSP-usability while satisfying all requirements (almost*) completely. Asterisks addressed later.
A simplified architecture diagram is shown in Figure 4.
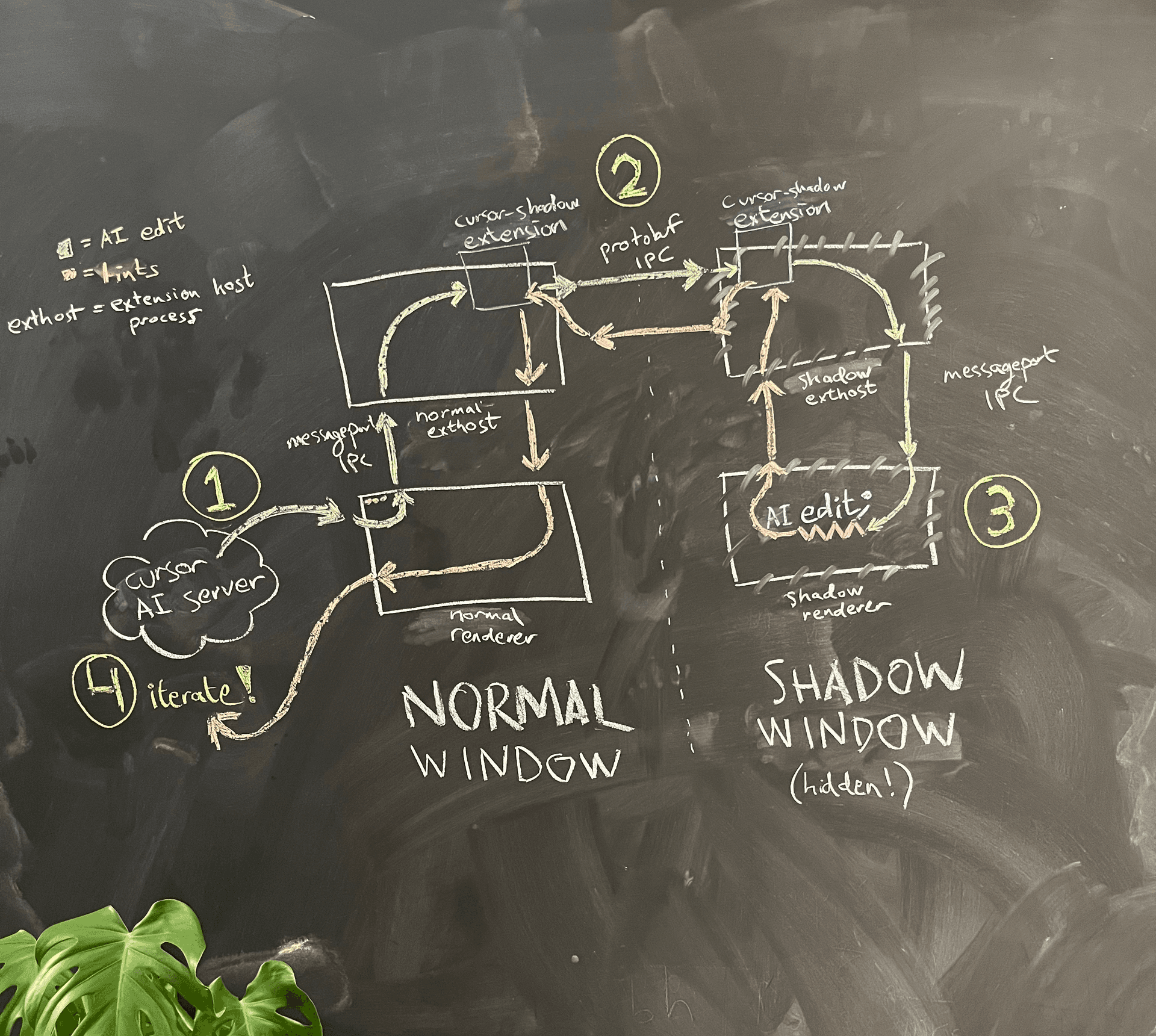
The AI is running in the renderer process of the normal window. When it wants to see lints for the code that it wrote, the renderer process asks the main process to spawn a hidden shadow window in the same folder.
Because of Electron sandboxing, the two renderer processes cannot communicate with each other directly. One option we considered was to reuse the careful message port creation logic that VS Code implemented to let the renderer process communicate with the extension host process, and use it to create our own message port IPC between the normal window and the shadow window. Wary of the maintainability burden, we opted for a hack: we reuse the existing message port IPC from the renderer process to the extension host, and then communicate from extension host to extension host using an independent IPC connection. There, we also snuck in a quality-of-life improvement: we could now use gRPC and buf (which we love) to communicate, instead of VS Code’s custom and somewhat brittle JSON serialization logic.
This setup is automatically quite maintainable, since the code added is independent from other code, and the core code required to hide the window is just one line (when opening a window in Electron, you can provide a parameter show: false to hide it). It trivially satisfies universality and privacy.
Fortunately, independence is also satisfied! The new window is completely independent from the user, so the AIs can freely do any changes they want to do and get the lints for them. The user won’t notice anything.
There is one concern with the shadow window: the new window naively comes with a 2x increase in memory usage. We reduce the impact of this by limiting the extensions that get to run in the shadow window, auto-killing it after 15 minutes of inactivity, and making sure that it is opt-in. Still, it poses a challenge for concurrency: we cannot simply spawn a new shadow window for each AI. Luckily, here we can take advantage of one of the key distinguishing factors between AIs and humans: AIs can be paused an indefinite amount of time without even noticing. In particular, if you have two AIs, A and B, proposing edits A1 followed by A2 and B1 followed by B2, respectively, you can interleave those edits. The shadow window first resets the entire folder state to A1, and gets the lints and returns them to A. Then, it resets the entire folder state to B1, and gets the lints and returns them to B. And so on and so forth with A2 and B2. In this sense, AIs are more similar to computer processes (which also get interleaved like this by the CPU without noticing) than humans (who have an intrinsic sense of time).
All of this taken together, we get a simple Protobuf API that our background AIs can use to refine their edits, without affecting the user at all.
The promised asterisks: Some language servers rely on code being written to disk before reporting lints. The main example is the rust-analyzer language server, which simply runs a project-level cargo check to get the lints, and does not integrate with the VS Code virtual file system (see this issue for reference). Thus, the shadow workspace does not yet support LSP-usability for Rust, unless the user is using the deprecated RLS extension.
Achieving runnability
Runnability is where things get both interesting and complicated. We are currently focusing on short-time-scale AIs for Cursor — say, implementing functions for you in the background while you use them, rather than implementing entire PRs — so we haven’t implemented runnability yet. Nevertheless, it is fun to think through how to achieve it.
Running code requires saving it to the file system. Many projects will also have disk-based side effects (think, build caches and log files). Hence, we can no longer launch the shadow window in the same folder as the user. For perfect runnability of all projects, we also need network-level isolation, but for now, we focus on achieving disk isolation.
The simplest idea: cp -r
The simplest idea is to recursively copy the user’s folder into a /tmp location, and then apply the AI edits, save the files, and run the code there. For the next edit by a different AI, we would do a rm -rf followed by a new cp -r call, to ensure that the shadow workspace stays in sync with the user’s workspace.
The problem is speed: cp -r is really slow. The thing to remember is that to be able to run a project, we not only need to copy the source code, but also all the supporting build-related files. Concretely, we need to copy the node_modules in JavaScript projects, the venv in Python projects, and the target in Rust projects. These are generally huge folders, even for medium-sized projects, spelling the end for the naive cp -r approach.
Symlinks, hardlinks, copy-on-writes
Copying and creating large folder structures doesn’t have to be super slow! An existence proof is bun, which often takes sub-second times for installing cached dependencies into node_modules. On Linux they use hardlinks, which is fast because there is no actual data movement. On macOS, they use the clonefile syscall which is a relatively recent addition that performs a copy-on-write of a file or folder.
Sadly, for our moderately sized monorepo, even a cp -c clonefile takes 45 seconds to finish. This is too slow to be run before every shadow workspace request. Hardlinks are scary because anything you run in the shadow folder may accidentally modify the real files in the original repository. Symlinks similarly so, and they also have the additional problem of not being treated transparently, meaning that they often require additional configuration (e.g. Node.js’s --preserve-symlinks flag).
One could imagine a clonefile (or even a plain cp -r) working out if coupled with some clever accounting scheme to prevent having to re-copy the folder before every request. To ensure correctness, we would need to monitor all file changes in the user’s folder since the last full copy, and all file changes in the copied folder, and before every request undo the latter and replay the former. Whenever the history of changes on either side becomes too big to keep track of, we could do a new full copy and reset the state. This could work, but it feels bug prone, brittle, and, frankly, a bit ugly for achieving something that sounds so simple.
What we really want: a kernel-level folder proxy
What we really want is simple: we want a shadow folder A′ to appear identical to the user’s folder A to all applications that are using the regular file system APIs, with the ability to quickly configure a small set of override files, whose contents are instead read from memory. We also want any writes to folder A′ to be written to the in-memory override store instead of to disk. In short, we want a proxy folder with configurable overrides, and we are happy to keep the override table entirely in memory. Then, we can spawn our shadow window inside this proxy folder, and achieve perfect disk-level independence.
Crucially, we need kernel-level support for the folder proxy, so that any running code can continue calling read and write syscalls without any changes. One approach is to create a kernel extension 13 that registers itself as a backend for the shadow folder in the kernel’s virtual file system, and implements the simple behavior outlined above.
On Linux we can do this at the user level instead, with FUSE (“Filesystem in Userspace”). FUSE is a kernel module that already exists in most Linux distributions by default, and proxies the file system calls out to a user-level process. This makes implementing the folder proxy even simpler. A toy implementation of the folder proxy could look like the following, here presented in C++.
First, we import the user-level FUSE library, which is responsible for communicating with the FUSE kernel module. We also define the target folder (the user’s folder) and the in-memory map of overrides.
#define FUSE_USE_VERSION 31
#include <fuse3/fuse.h>
// other includes...
using namespace std;
// the proxied folder that we do not want to modify
string target_folder = "/path/to/target/folder";
// the in-memory overrides to apply
unordered_map<string, vector<char>> overrides;Then, we define our custom read function to check if the overrides contain the path, and if not, just read from the target folder.
int proxy_read(const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// check if the path is in the overrides
string path_str(path);
if (overrides.count(path_str)) {
const vector<char>& content = overrides[path_str];
// if so, return the content of the override
if (offset < content.size()) {
if (offset + size > content.size())
size = content.size() - offset;
memcpy(buf, content.data() + offset, size);
} else {
size = 0;
}
return size;
}
// otherwise, open and read the file from the proxied folder
string fullpath = target_folder + path;
int fd = open(fullpath.c_str(), O_RDONLY);
if (fd == -1)
return -errno;
int res = pread(fd, buf, size, offset);
if (res == -1)
res = -errno;
close(fd);
return res;
}Our custom write function simply writes to the overrides map.
int proxy_write(const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// always write to the overrides
string path_str(path);
vector<char>& content = overrides[path_str];
if (offset + size > content.size()) {
content.resize(offset + size);
}
memcpy(content.data() + offset, buf, size);
return size;
}Finally, we register our custom functions with FUSE.
int main(int argc, char *argv[])
{
struct fuse_operations operations = {
.read = proxy_read,
.write = proxy_write,
};
return fuse_main(argc, argv, &operations, NULL);
}A real implementation would need to implement the entire FUSE API, including readdir and getattr and lock, but the functions would just be very similar to the ones above. For every new request for lints, we can simply reset the overrides map to just that specific AI’s edits, which is instant. If we wanted to guarantee against a memory blowup, we could also keep the overrides map on disk (with some extra bookkeeping work).
With perfect control over the environment, we’d likely want to implement this as a native kernel module instead, to avoid the overhead of the extra user-kernel context switching from FUSE. 14
...But: walled gardens
For Linux, the FUSE folder proxy works great, but most of our users use macOS or Windows, neither of which have a built-in FUSE implementation. Unfortunately, shipping a kernel extension is also out of question: on Macs with Apple Silicon, the only way for a user to install a kernel extension is to reboot the computer while holding down a special key to enter recovery mode, and then downgrading to “Reduced Security”. Unshippable!
Since FUSE partially needs to run inside the kernel, third-party FUSE implementations like macFUSE suffer from the same impossible-to-get-users-to-install-it problem.
There have been attempts to get creative around this restriction. One approach is to take a network-based file system that macOS does support natively (e.g., NFS or SMB), and put a FUSE API underneath it. There’s an open-source proof-of-concept local server with a FUSE-like API built on top of NFS hosted at xetdata/nfsserve, and the closed-source project macOS-FUSE-t supports backends built on both NFS and SMB.
Problem solved? Not really... File systems are more complicated than just reading, writing, and listing files! Here, Cargo complains because earlier versions of NFS, that the xetdata/nfsserve implementation is built on, do not support file locking.

MacOS-FUSE-t is built on NFSv4 which does support file locking, but the GitHub repo contains nothing but three non-source files (Attributions.txt, License.txt, README.md), and is created by a GitHub account with the suspiciously single-purpose username macos-fuse-t with no further information. Obviously, we cannot ship random binaries to our users... The open issues also indicate some more fundamental problems with the NFS/SMB-based approach, mostly related to Apple kernel bugs.
What are we left with? Either a new creative approach, 15 or... politics! Apple’s decade-long journey to phase out kernel extensions has led them to open up more and more user-level APIs (such as DriverKit), and their built-in support for old file systems has recently been switched over to user-land. Their open source MS-DOS code references a private framework called FSKit here, which sounds very promising! It feels possible that with a little bit of politics, we could get them to finalize and release FSKit to external developers (or perhaps they are already planning to?), in which case we might have a solution to the runnability problem for macOS too.
Open questions
As we have seen, the seemingly simple problem of letting AIs iterate on code in the background is actually quite complex. The shadow workspace was a 1-week, 1-person project to create an implementation to solve the immediate need that we had of showing lints to the AI. In the future, we are planning to extend it to also solve the runnability problem. A few open questions:
-
Is there another way to do the simple proxy folder we are thinking of without creating a kernel extension or using the FUSE API? FUSE tries to solve a bigger problem (any kind of file system), and so it feels plausible that there could be some obscure APIs on macOS and Windows that work for our folder proxy but would not work for a general FUSE implementation.
-
What exactly does the story for the proxy folder look like on Windows? Would something like WinFsp just work, or are there installation, performance or security problems with that? I spent most of my time looking into how to do the folder proxy on macOS.
-
Perhaps there’s a way to use DriverKit on macOS and simulate a fake USB device to act as the proxy folder? I doubt it, but I haven't looked into the API closely enough to confidently say that it is impossible.
-
How can we achieve network-level independence? One particular situation to consider is when the AI wants to debug an integration test where the code is split between three microservices. 16 It is possible that we want to do something more VM-like, although that will require more work to ensure equivalence for the entire environment setup and all installed software.
-
Is there a way to create an identical remote workspace from the user’s local workspace with as little setup needed from the user as possible? In the cloud, we could use FUSE out of the box (or even a kernel module if desired for performance reasons) without doing any politics, and we could also guarantee no extra memory usage for the user and complete independence. For users who care less about privacy, this could be a good alternative. One proto-idea is some kind of auto-inferred docker container by observing the system (perhaps using a combination of writing scripts to detect what's running on the machine, and using language models to write a Dockerfile).
If you have good ideas for any of these questions, please email me at arvid@cursor.com. Also, if you’d like to work on things like this, we’re hiring.